什么是网络协议?网络协议指的是计算机网络中互相通信的对等实体之间交换信息时所必须遵守的规则的集合,是网络上所有设备(网络服务器、计算机及交换机、路由器、防火墙等)之间通......
spss缺失值填补方法有哪些
电脑教程
2022-04-21 21:48:42
1、均值插补。数据的属性分为定距型和非定距型。如果缺失值是定距型的,就以该属性存在值的平均值来插补缺失的值;如果缺失值是非定距型的,就根据统计学中的众数原理,用该属性的众数(即出现频率最高的值)来补齐缺失的值。
2、利用同类均值插补。同均值插补的方法都属于单值插补,不同的是,它用层次聚类模型预测缺失变量的类型,再以该类型的均值插补。假设X=(X1,X2...Xp)为信息完全的变量,Y为存在缺失值的变量。
那么首先对X或其子集行聚类,然后按缺失个案所属类来插补不同类的均值。如果在以后统计分析中还需以引入的解释变量和Y做分析,那么这种插补方法将在模型中引入自相关,给分析造成障碍。
3、极大似然估计(Max Likelihood ,ML)。在缺失类型为随机缺失的条件下,假设模型对于完整的样本是正确的,那么通过观测数据的边际分布可以对未知参数进行极大似然估计(Little and Rubin)。
这种方法也被称为忽略缺失值的极大似然估计,对于极大似然的参数估计实际中常采用的计算方法是期望值最大化(Expectation Maximization,EM)。
4、多重插补(Multiple Imputation,MI)。多值插补的思想来源于贝叶斯估计,认为待插补的值是随机的,它的值来自于已观测到的值。具体实践上通常是估计出待插补的值,然后再加上不同的噪声,形成多组可选插补值。根据某种选择依据,选取最合适的插补值。
扩展资料
缺失值产生的原因很多,装备故障、无法获取信息、与其他字段不一致、历史原因等都可能产生缺失值。一种典型的处理方法是插值,插值之后的数据可看作服从特定概率分布。另外,也可以删除所有含缺失值的记录,但这个操作也从侧面变动了原始数据的分布特征。
对于缺失值的处理,从总体上来说分为删除存在缺失值的个案和缺失值插补。对于主观数据,人将影响数据的真实性,存在缺失值的样本的其他属性的真实值不能保证,那么依赖于这些属性值的插补也是不可靠的,所以对于主观数据一般不推荐插补的方法。插补主要是针对客观数据,它的可靠性有保证。
标签: spss缺失值填补方法
相关文章
- 详细阅读
-
区块链核心技术体系架构的网络层主要包括什么详细阅读
区块链核心技术体系架构的网络层主要包括:A、网络管理B、P2P网络C、HTD、发现节点E、心跳服务网络管理网络管理包括对硬件、软件和人力的使用、综合与协调,以便对网络资源进行监视......
2022-04-28 328 区块链核心技术
-
软件调试的目的是什么详细阅读
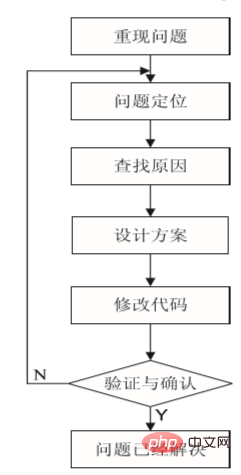
软件调试的目的是:改正错误。软件调试的概念软件调试是泛指重现软件缺陷问题,定位和查找问题根源,最终解决问题的过程。软件调试通常有如下两种不同的定义:定义1:软件调试是为了......
2022-04-28 359 软件调试
- 详细阅读
- 详细阅读