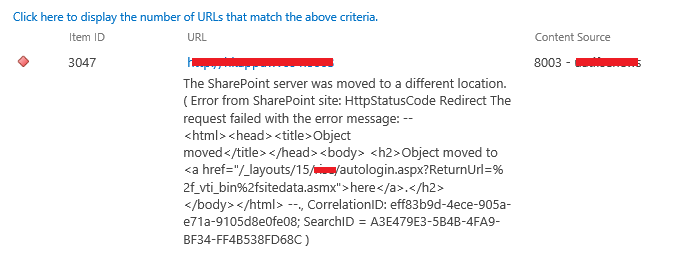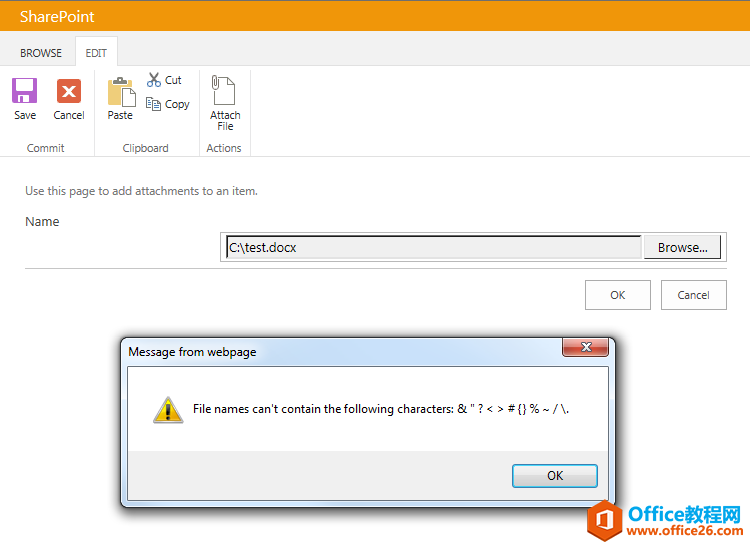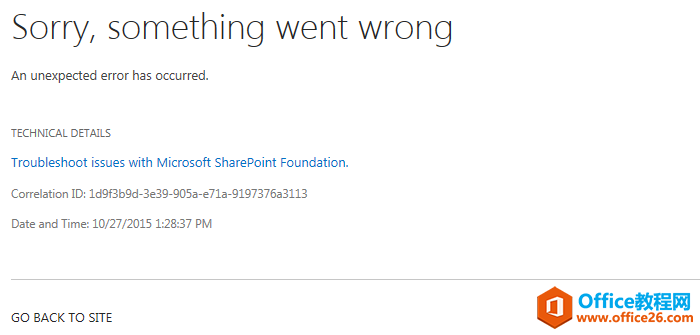
错误截图错误日志位置:C:\ProgramFiles\CommonFiles\microsoftshared\WebServerExtensions\15\LOGS主要错误ThecurrentuserisnotanSharePointServerfarmadministrator.处理过程查看了当前User确实不是场管理员,但......
2022-04-11 67 SharePoint ERROR the current user not Server farm 错误
思路:由于SharePoint的架构和Net有着不一样的特点,而且SharePoint的数据库设计是不为人所知的(当然我们可以了解一些,但不完全),虽然也是基于Net架构的,但是我们很难做到Sql To Sql的方式。所以,只能考虑服务器端对象模型,插入到数据库中的方式,其间,经理给的建议非常合理,就是将SharePoint的数据整理好插入中间库,然后统一插入到新网站数据库中。在后来的实践中,发现这一方法对数据迁移和检查,都有着非常好的帮助,避免了很多SharePoint对象模型中出错,但是不好更正的现象。
中间库设计:
考虑到原内网门户有列表、文档库、图片库三种主要类型(特殊列表特殊对待),所以创建了两个数据库表,分别用来存List和DocLib,同时再创建两个表Image和Attachment用来存列表正文中的图片和列表附件(文档库文档当做列表附件)。
一、用来存储列表内容的表 -- TABLE [dbo].[List]
+ View Code?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | [ID] [int] IDENTITY(1,1) NOT NULL,--主键ID [WebID] [nvarchar](max) NULL,--所在网站的Guid [ListID] [nvarchar](max) NULL,--所在列表的Guid [ListName] [nvarchar](max) NULL,--列表名称 [ContentType] [nvarchar](max) NULL,--所属内容类型 [ItemID] [nvarchar](max) NULL,-- 列表里面的ID [ApprovalState] [int] NULL,--审批状态 [Title] [nvarchar](max) NULL,--标题 [SubTitle] [nchar](10) NULL,--副标题 [ItemContent] [nvarchar](max) NULL,--内容 [Creator] [nvarchar](max) NULL,--创建者LoginName [CreatorID] [nvarchar](max) NULL,--创建者UserID [DispCreator] [nvarchar](max) NULL,--创建者UserName [Modifier] [nvarchar](max) NULL,--修改者LoginName [ModifierID] [nvarchar](max) NULL,--修改者UserID [DispModifier] [nvarchar](max) NULL,--修改者UserName [CreatTime] [datetime] NULL,--创建时间 [ModifyTime] [datetime] NULL,--修改时间 [TransferDate] [datetime] NULL,--数据迁移时间 |
二、用来存储文档库/图片库的表 -- TABLE [dbo].[DocLib]
+ View Code?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | [ID] [int] IDENTITY(1,1) NOT NULL,--主键ID [WebID] [nvarchar](max) NULL,--所在网站的Guid [ListID] [nvarchar](max) NULL,--所在列表的Guid [ListName] [nvarchar](max) NULL,--列表名称 [ListType] [nvarchar](max) NULL,--列表类型(文档库/图片库) [ItemID] [nvarchar](max) NULL,-- 列表里面的ID [ApprovalState] [int] NULL,--审批状态 [Title] [nvarchar](max) NULL,--标题 [Creator] [nvarchar](max) NULL,--创建者LoginName [CreatorID] [nvarchar](max) NULL,--创建者UserID [DispCreator] [nvarchar](max) NULL,--创建者UserName [Modifier] [nvarchar](max) NULL,--修改者LoginName [ModifierID] [nvarchar](max) NULL,--修改者UserID [DispModifier] [nvarchar](max) NULL,--修改者UserName [CreatTime] [datetime] NULL,--创建时间 [ModifyTime] [datetime] NULL,--修改时间 [Url] [nvarchar](max) NULL,--文档的Url [TransferDate] [datetime] NULL,--数据迁移时间 |
三、用来存储正文图片的表 -- TABLE [dbo].[Image]
+ View Code?| 1 2 3 4 5 6 7 | [ID] [int] IDENTITY(1,1) NOT NULL,--主键ID [WebID] [nvarchar](max) NULL,--所在Web的Guid [WebSubUrl] [nvarchar](max) NULL,--所在Web的相对WebUrl [ListID] [nvarchar](max) NULL,--所在列表的Guid [ListName] [nvarchar](max) NULL,--列表名称 [ItemID] [nvarchar](max) NULL,-- 列表里面的ID [ImageUrl] [nvarchar](max) NULL,--内容图片的Url,多张图片,逗号分隔 |
四、用来存储附件集的表 -- TABLE [dbo].[Attachment]
+ View Code?| 1 2 3 4 5 6 7 | [ID] [int] IDENTITY(1,1) NOT NULL,--主键ID [WebID] [nvarchar](max) NULL,--所在Web的Guid [WebSubUrl] [nvarchar](max) NULL,--所在Web的相对WebUrl [ListID] [nvarchar](max) NULL,--所在列表的Guid [ListName] [nvarchar](max) NULL--列表名称 [ItemID] [nvarchar](max) NULL,-- 列表里面的ID [AttachUrl] [nvarchar](max) NULL,--附件的Url,多个的时候,逗号分隔 |
代码方法段:
首先就是对象模型读取列表插入List表,然后是对象模型读取文档库/图片库插入DocLib表,读取字段的代码比较简单,我们就不过多介绍,就介绍下其间遇到的几个问题,也避免代码太多太繁杂。
问题一:正文乱码
这是一个比较操心的问题,插入数据没有问题,但是到新系统显示,发现好多正文带有雷系”?“之类的东西,这样子肯定不行,首先想到RePlace,然后想想不太靠谱,因为正文里很有可能有正常的问号,这样会被替换掉。后来想到可能是编码问题,后来证实确实是编码问题,将特别的空格处理替换为即可,处理如下:
?| 1 2 3 4 5 6 | //Content替换空格为 byte[] space = new byte[] { 0xc2, 0xa0 }; string UTFSpace = System.Text.Encoding.GetEncoding("UTF-8").GetString(space); Content = Content.Replace(UTFSpace, " "); Content = DeleteHtmlImgTag(Content); Content = Content.Replace("'", "''"); |
问题二 处理中途报错
插入过程中,我们会出现一些操作异常的情况,可能整个程序要运行4-5个小时,但是4个小时的时候,出现异常了,我们很恼火,调试也很困难,因为很难去调试问题,即使把断点打在Catch里面,调试也是力不从心的,所以,我们必须一次成功,不容许中间出差错。这样,我采取了空跑程序(只走对象模型,不插入数据库,因为Insert很慢,而且几乎不报错,错误多数出现在对象模型调用上,各种字段没有、对象为空)和记录错误补录两个方式,来避免这样的问题。
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 | public static void WriteErrorLog(string ErrorMessage) { try { using (StreamWriter sw = File.AppendText(@"log_error " + InsertTime.ToString("yyyy-MM-dd HHmmss") + ".txt")) { sw.WriteLine(ErrorMessage); sw.Dispose(); } } catch{ } Console.WriteLine(ErrorMessage); } |
问题三 处理中间的小错误
操作过程中,对于代码编写的可靠性,要求很好,就像上面所说,一个要跑4-5个小时的程序,4个小时的时候报错,我们基本就属于前功尽弃,因为继续插入是很困难的。所以中间的小问题,对于代码段的可靠性要求,就非常高了。必要的时候,多加一些Try...Catch...可能会对于效率有一点点影响,但是对于整个程序来说,是非常必要的。
?| 1 2 3 4 5 6 | if (!web.Exists){}//判断web是否存在 list = web.Lists[ListName];//打开的时候Try一下,避免不存在,ListName最好Trim一下 if (list.BaseTemplate == SPListTemplateType.Announcements)//判断list类型 if (list.Fields.ContainsField("SubTitle"))//判断是否有SubTitle这个字段 //副标题对象不为空,才赋值,否则赋值为空字符串(下面那行的注释…) SubTitle = (item["SubTitle"] == null) ? string.Empty : item["SubTitle"].ToString(); |
问题四 提取正文中的图片URL
我们数据迁移过程,正文中会带有图片,这就要求我们把图片保存下来,迁移过去,然后还要插入到相同的位置。这是个比较让人头疼的问题,首先说下逻辑,读取正文的时候,用正则表达式获取所有的图片(不是绝对路径的要拼成绝对路径),然后插入到Image中间库中,将原来图片的位置,替换为一个图片标志,因为之后我们还要把图片插入到这里。
?| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | /// /// 取得HTML中所有图片的 URL。 /// /// HTML代码 /// public static string[] GetHtmlImageUrlList(string sHtmlText) { // 定义正则表达式用来匹配 img 标签 Regex regImg = new Regex(@", RegexOptions.IgnoreCase); // 搜索匹配的字符串 MatchCollection matches = regImg.Matches(sHtmlText); int i = 0; string[] sUrlList = new string[matches.Count]; // 取得匹配项列表 foreach (Match match in matches) sUrlList[i++] = match.Groups["imgUrl"].Value; return sUrlList; } |
问题五 将正文中的图片Url换为标识
同样使用正则表达式,将图片标签
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | /// /// 去处HTML中所有图片的img标签。 /// /// HTML代码 /// public static string DeleteHtmlImgTag(string sHtmlText) { string result = Regex.Replace(sHtmlText, @", delegate(Match m) { return "; }); if (result.IndexOf("") > 0) { result = result.Replace("", ""); } if (result.IndexOf("") > 0) { result = result.Replace("", ""); } return result; } |
中间库到新系统:
经过将SharePoint中数据,整理插入到中间库的过程,我们等于已经完成80%的工作,因为剩下的内容,就是Sql To Sql的问题了,对于net开发人员,甚至不需要设计,你只需要了解新系统的数据库结构,相应字段插入就可以了。唯一要提到的就是附件/图片处理的问题,下面我说下我的处理方式:
附件/图片处理
这也是一个比较棘手的问题,因为众所周知的原因,SharePoint的附件/图片是BLOB的形式,存储在数据库中的(我尝试去数据库中找这个字段,没找到);所以我们只能用对象模型,当然SPFile是我们第一时间想到的,但是效率可想而知(效率太慢放弃);所以考虑先将附件/图片的Url地址拼接好,插入到Images/Attachment的中间库中,然后采取WebClient的对象去下载为Byte[],然后直接上传,测试结果还是很客观的,100个附件1分钟左右(与附件大小有关)。
?| 1 2 3 4 5 6 7 | using (WebClient wc = new WebClient()) { NetworkCredential networkCredential = new NetworkCredential("用户名", "密码", "域"); wc.Credentials = networkCredential; byte[] ss = wc.DownloadData(url); return ss; } |
总结:数据迁移过程比较繁杂,需要考虑的东西比较多,前期的规划很重要,因为数据一旦迁移过去,修修补补会很让人郁闷,所以对应关系一定一定要先做好,避免后期修改。而且,两边系统的开发人员对接非常重要,避免出现少插入字段等现象,造成新系统出问题。基本上就是以上这些,写出来给有需要的人们参考下,就这样了。
相关文章
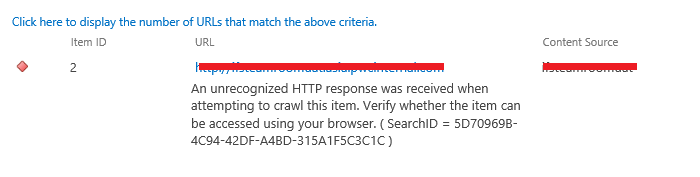
SharePoint2013爬网报错AnunrecognizedHTTPresponsewasreceivedwhenattemptingtocrawlthisitem.Verifywhethertheitemcanbeaccessedusingyourbrowser.然后登陆网站,发现在服务器上输入3次用户名密码白页,考虑到......
2022-04-11 449 SharePoint ERROR unrecognized HTTP response was received
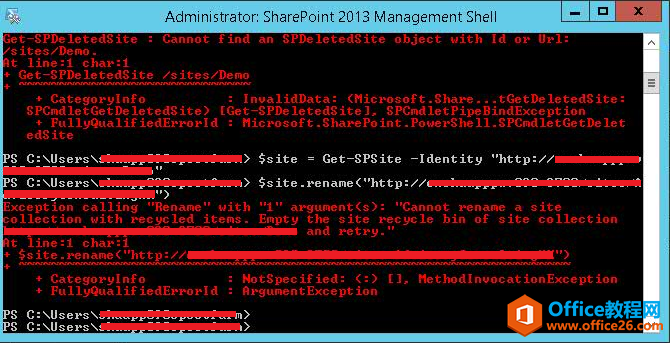
最近使用SharePoint中,遇到一个需要重命名网站集的需求,主要是网站用数据库备份/还原的方式,想要改网站集的地址,然后搜了一下PowerShell:$site=Get-SPSite-Identityhttp://server/sites/Demo$site.......
2022-04-11 299 SharePoint重命名网站集名称